I paid heed to the Data Science call the moment I enrolled for one machine learning course on Coursera. Of course, I didn’t have the money to take up the course but I’m glad they accepted me anyway. All I can say is the instructors were brilliant; Carlos and Emily. I’m your proud student as much as I didn’t clear the entire course set. I wouldn’t say I was naive in the field as I had read books as well as machine learning papers before.
For the past two or so weeks, I keenly thought through what projects I could do to improve my data analysis knowledge. Being Kenyan and reading negative news about my national airline KQ slowdown in operations, I deemed it fit to look at the airline performance in terms of customers feedback. The airline industry is very competitive therefore having planes is not enough for a company. Service delivery is what differentiates the airlines as customers think of quality and comfort when traveling more than anything else. Our data perspective below is quite straightforward.
Data Collection
Any data science practitioner will agree with me that however huge/small a data job is, the secret to good results lies in the data. The collection source/method all the way to how clean and present it takes up the bulk of the task execution time. I settled on two websites to get user reviews about the airline. Airline quality as well as TripAdvisor were the source of concise reviews. Skytrax has always depended on the same review metrics to rate airlines and airports for quite a while. I scraped all reviews affiliated to Kenya Airways, my entity of choice, using the Data Miner Chrome extension. It worked well for me. A sample representation of the entire set is still a feasible idea but the fact that they were just 528 I found it ok to use the entire set. Hopefully, my custom made Python scraper will be done by the time I get to look for the next dataset. The attributes factored in included the review itself and the user rating. Point to note is that the Airquality ratings range between 1-10 while the Tripadvisor ones just range from 1-5. They are all classified as below.
| Airline Quality |
Trip Advisor |
Polarity |
What this means |
| 1-4 |
1-2 |
Negative |
User is disappointed in the airline. This is our point of interest and I’m sure is KQs |
| 5 |
3 |
Neutral |
User holds a neutral opinion. Not bad/good |
| 6-10 |
4-5 |
Positive A |
User is satisfied with the airline |
Data Analysis
R a statistical and machine learning tool was the choice for this analysis task. The most important package in this task was the Text mining one; library(“tm”).Data munging/wrangling which I’m to apply on the data, is defined as the process of manually converting or mapping data from one “raw” form into another format that allows for more convenient consumption of the data with the help of semi-automated tools(R in our case). Lets head straight to the task at hand.
>prop.table(table(KQ_Entire_Dataset$Polarity))
>subset_data = as.data.frame(prop.table(table(KQ_Entire_Dataset$Polarity)))
>colnames(subset_data) = c("Sentiment","Proportion")> View(subset_data)
The command helped in generating 3 proportions of the datasets representing the three classes in question. After all, we need to know what sentiments outweighs the others.

Positive sentiments outweighed the rest but still 34% being negative is huge. It’s an airline remember where quality has to always be right.A graphical representation of the same is as below. The R code to generate the same is as follows.
blank_theme = theme_minimal() + theme(
axis.title.x = element_blank(),axis.title.y = element_blank(),panel.border = element_blank(),axis.ticks = element_blank(),
plot.title = element_text(size = 14, face = 'bold') )
gbar = ggplot(subset_data, aes(x = Sentiment, y = Proportion, fill = Sentiment))
gpie = ggplot(subset_data, aes(x = "", y = Proportion, fill = Sentiment))
plot1 = gbar + geom_bar(stat = 'identity') + ggtitle("Overall Sentiment") + theme(plot.title = element_text(size = 14, face = 'bold', vjust = 1),axis.title.y = element_text(vjust = 2), axis.title.x = element_text(vjust = -1))
plot2 = gpie + geom_bar(stat = 'identity') + coord_polar("y", start = 0) + blank_theme + theme(axis.title.x = element_blank()) + geom_text(aes(y = Proportion/3 + c(0, cumsum(Proportion)[-length(Proportion)]),label = round(Proportion, 2)), size = 4) + ggtitle('Overall Sentiment')
grid.arrange(plot1, plot2, ncol = 1, nrow = 2)

Hopefully, I will remember loading datasets for about 4 more airlines and draw a side by side comparison in the next post. For now, the above representation should be enough. You at least have an idea of how the subset proportions look like.
We can now delve deeper in understanding the sentiments in the reviews. What did customers talk most about negatively or positively? I’m sure the negative proportion is what KQ and by extension, any service agent would be interested in. The dataset was subdivided into two subsets. Those with a negative and positive polarity then analyzed further. The commands are as below.
> positive_subset = subset(KQ_Entire_Dataset, Polarity == 'Positive')
> negative_subset = subset(KQ_Entire_Dataset, Polarity == 'Negative')
> dim(positive_subset); dim(negative_subset)
[1] 257 3
[1] 181 3
257 of the reviews were positive compared to 181 being negative. We’ll henceforth ignore the neutral sentiments as we believe do not represent the points of interest here. A wordcloud representation will paint a better picture of the focal points in the review. We made the data presentable before going ahead plotting it.
# these words appeared frequently in the reviews and in our judgement
did not have an impact that much on the reviews.
> wordsToRemove = c('get', 'X767','also', 'can', 'now', 'just', 'will','
MoreÂ','moreâ','veri','International','Economy','London','Yaoundé','Douala',
'Libreville','Brazzaville','Kinshasa','Bujumbura','Djibouti','Cairo',
'Addis Ababa','Kigali','Khartoum','Juba','Dar es Salaam','Entebbe','Kampala',
'Paris','Amsterdam','amsterdam','London','Guangzhou','Hong Kong','Bangkok',
'Hanoi','Dubai','Johannesburg','Cape Town','Luanda','Gaborone','Comoros',
'Antananarivo','Lilongwe','Maputo','Seychelles','Lusaka','Harare',
'Porto Novo','Benin','Ouagadougou','Accra','Abidjan','Monrovia','Bamako',
'Lagos','Dakar','Freetown','Mumbai')
>
> # generate a function to analyse corpus text
> analyseText_1 = function(text_to_analyse){
+ # analyse text and generate matrix of words
+ # Returns a dataframe containing 1 review per row, one word per column
+ # and the number of times the word appears per tweet
+ CorpusTranscript = Corpus(VectorSource(text_to_analyse))
+ CorpusTranscript = tm_map(CorpusTranscript, content_transformer(tolower), lazy = T)
+ CorpusTranscript = tm_map(CorpusTranscript, PlainTextDocument, lazy = T)
+ CorpusTranscript = tm_map(CorpusTranscript, removePunctuation)
+ CorpusTranscript = tm_map(CorpusTranscript, removeWords, wordsToRemove)
+ CorpusTranscript = tm_map(CorpusTranscript, stemDocument, language = "english")
+ CorpusTranscript = tm_map(CorpusTranscript, removeWords, stopwords("english"))
+ CorpusTranscript = DocumentTermMatrix(CorpusTranscript)
+ CorpusTranscript = removeSparseTerms(CorpusTranscript, 0.97) # keeps a matrix 97% sparse
+ CorpusTranscript = as.data.frame(as.matrix(CorpusTranscript))
+ colnames(CorpusTranscript) = make.names(colnames(CorpusTranscript))
+ return(CorpusTranscript)
+ }
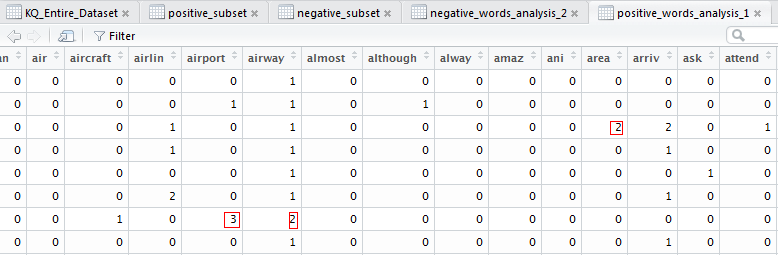
The above function transforms the data from its current raw form to a matrix form for better representation of how many times a word appears in a document(each review in this case). Basically is the Term Frequency (TF) part. We then applied the function on the negative subset of the entire corpus.
dim(negative_words_analysis_2)
[1] 181 286
> negative_words_analysis_2 = analyseText_1(negative_subset$Review_name)
> freqWords_neg = colSums(negative_words_analysis_2)
> freqWords_neg = freqWords_neg[order(freqWords_neg, decreasing = T)]
The function extracted 286 words (1 per column) that are repeated with certain frequency across all negative reviews. We’ll have a look at them too in a short while.
The output is as below.

A summation of their frequencies in a negative context is arrived at by issuing the below commands.
>freqWords_neg = colSums(negative_words_analysis)
> freqWords_neg = freqWords_neg[order(freqWords_neg, decreasing = True)]
> freqWords_neg[0:15]
The output is as below:-
flight nairobi kenya hour airway staff time
332 189 106 100 95 82 81
delay seat airline economy food passengers service
77 77 76 68 63 63 62
“Flight” is the most common word in the negative reviews as well as “Nairobi”, “Kenya” etc in that order. That was expected as most customers will make reference to the flight they were taking to Nairobi (destination/connection port for Kenya Airways). The entity to note is “hour” and “staff”. Going through the reviews paints a picture of delays and not very friendly staff on the negative side. On the contrary, it’s also possible to find the same aspects on the positive side of the reviews. One man’s meat is another man’s poison.
positive_words_analysis_1 = analyseText_1(positive_subset$Review_name)
> dim(positive_words_analysis_1)
[1] 257 219
In the 257 positive sentiments, the most frequent words were 219.Some words e.g. “flight” dominated both subsets.
> freqWords_pos = colSums(positive_words_analysis_1)
> freqWords_pos = freqWords_pos[order(freqWords_pos, decreasing = T)]
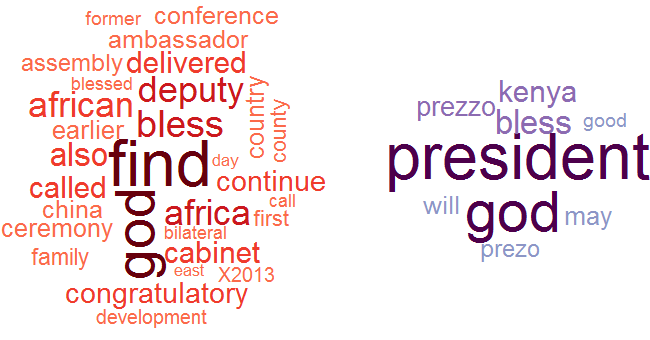
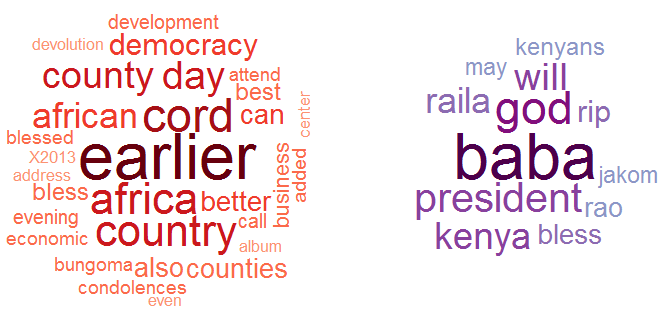
A side by side word cloud representation of the evident words in the negative and positive reviews respectively is as below. The size of the word correlates to its frequency across all the reviews.

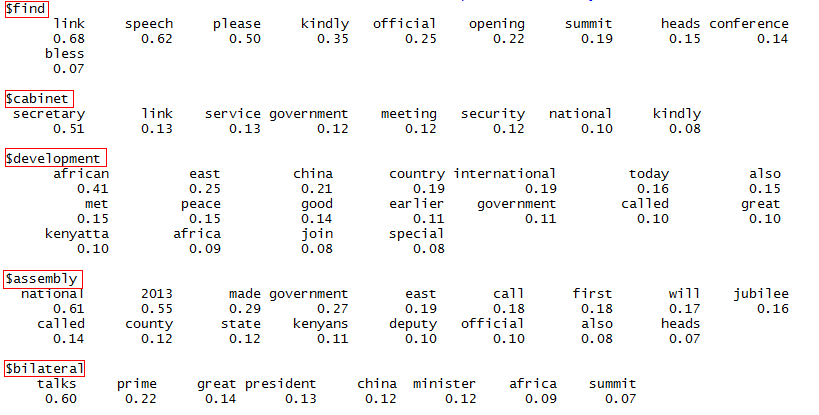
The final part is in finding associations between words, both in the positive and negative subsets. For example, what word followed e.g. “flight” or “staff” in the two subsets. This will give us a better idea of what aspects KQ can look at to improve. We’ll, therefore, look at the words correlated to the top 10 most frequent words in each of the subsets. Correlation is put at 70%.
>neg_words = analyseText_3(negative_subset$Review_name)
> findAssocs(neg_words, c(“flight”, ‘staff’,’delay’,’food’,’service’), .07)

We repeated the same procedure with the positive subset of the data. Correlation is still at 70%.
> pos_words = analyseText_3(positive_subset$Review_name)
> findAssocs(pos_words, c("flight", 'time','crew','food','service','seat','customer'), .07)


Conclusion
I’m sure you now have an idea of why the KQ story had to be told this way. We got data, wrangled it to a form understandable by the computer and presented the final findings. It’s NOT upon us to give ways forward on what the management of KQ needs to do as the data to some extent speaks it loud. It’s up to the firm to work on the negative aspects. We shall continue to analyze datasets from other airlines that fly the Nairobi route to know why they are performing better if not worse compared to KQ. We also do not rule out analyzing data from other disparate sources e.g. social media accounts of the airline that are rich with user feedback. Keep following us and hey we are happy to receive your feedback.